Measuring terminal Unicode width has always been a difficult problem. Per-terminal correction tables make near-perfect accuracy possible.
In past years, I have published a specification of Python wcwidth, and Kovid Goyal has published "The algorithm for splitting text into cells" as part of the Kitty Text Sizing protocol.
Terminal emulator authors have agreed to disagree on many broad interpretations of Unicode standards, such as whether emoji should be supported at all, down to the very fine details of individual codepoints, categories, and grapheme widths.
We continue to await Fraser Gordon of the Unicode Text Terminal Working Group to publish standards. After 12 and 6 years of improving the Python wcwidth and ucs-detect libraries, I suggest the "Terminal Unicode Width" problem cannot be solved by clear specification, implementation, and compliance reporting alone.
Modelike 2027
The design of DEC Private Mode 2027 (Grapheme Clustering, 2021) is a binary indicator of whether a terminal reports to support grapheme clustering. Hashimoto's Grapheme Clusters and Terminal Emulators (2023) explains the mode plainly for a single ZWJ codepoint.
But grapheme support is not a binary indicator of terminal width measurements. With ucs-detect, I have measured:
- 23 implementations of which codepoints are Wide (WIDE).
- 21 implementations of language grapheme support (LANG).
- 19 implementations of complex emoji joined with a Zero-Width Joiner (ZWJ): 👩🏻❤💋👩🏿.
- 7 and 6 implementations of widths of emojis combined with Variation Selector-15 and 16: ❤️.
- 2 implementations of standalone Fitzpatrick (SFZ): 🏻🏼🏽🏾🏿
- 2 implementations of standalone Regional Indicators (SRI): 🇸.
- 2 implementations of Zero-Width for invisible Format characters (Cf).
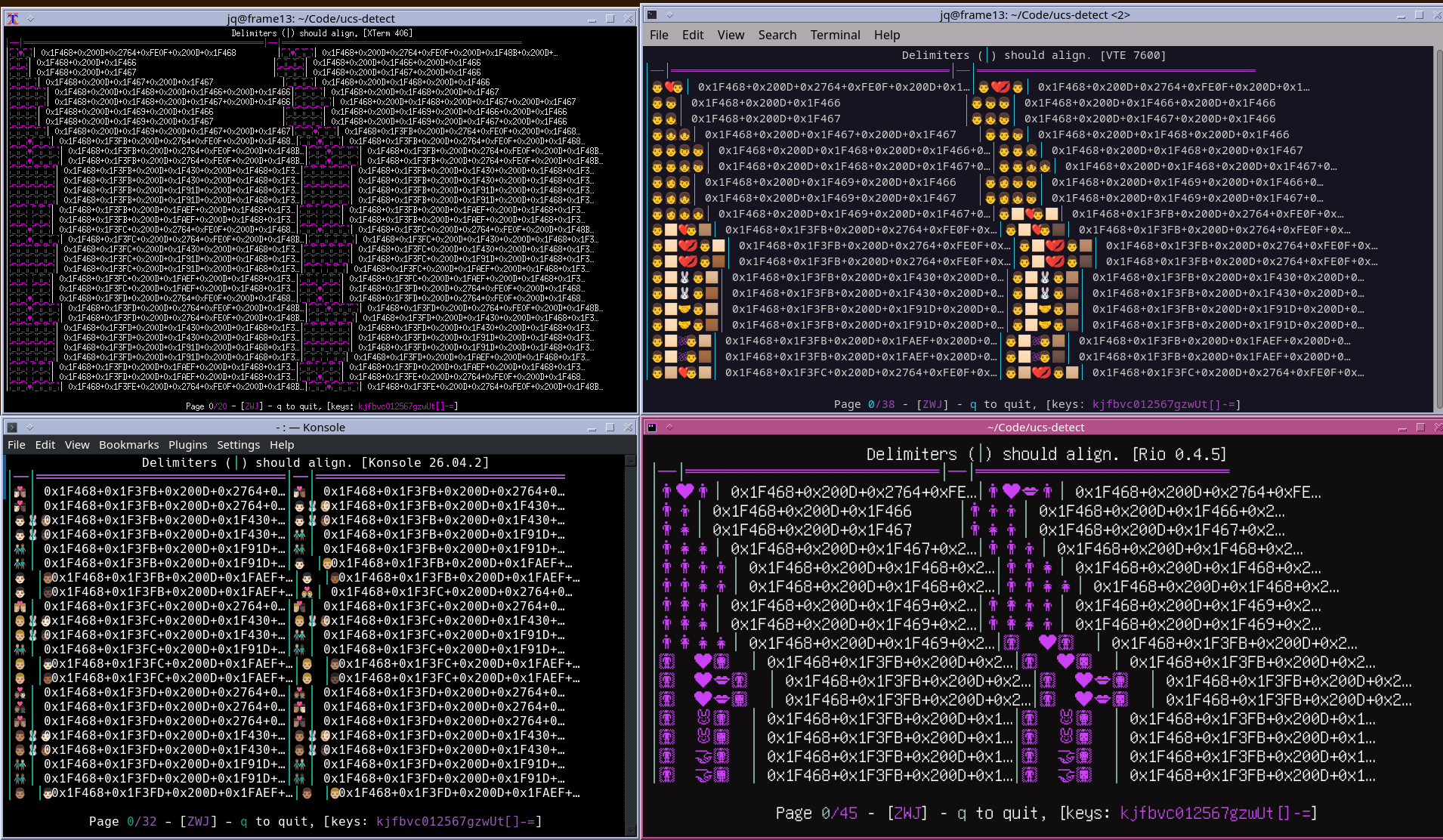
Linux screenshots XTerm, Gnome, Konsole, and Rio without Mode 2027 support
Among terminals enabled for mode 2027, there is still some variance, though mild:
- 6 implementations of language grapheme support (LANG).
- 5 implementations of which characters are Wide (WIDE).
- Contour measures 54 emoji with Zero-Width Joiners (ZWJ) as Narrow instead of Wide.
- Contour and WezTerm are missing Variation-Selector 16 (VS16) support for some early emojis: #️*️0️1️2️3️4️5️6️7️8️9️
- foot, WezTerm, and Windows Terminal measure standalone Regional Indicators (SRI) as Narrow instead of Wide.
- foot and Windows Terminal measure Fitzpatrick modifiers (🏻🏼🏽🏾🏿) as width of 1 instead of 2.
- 14 Format characters (Category Cf) are in dispute as width 1 or 0 for many terminals.
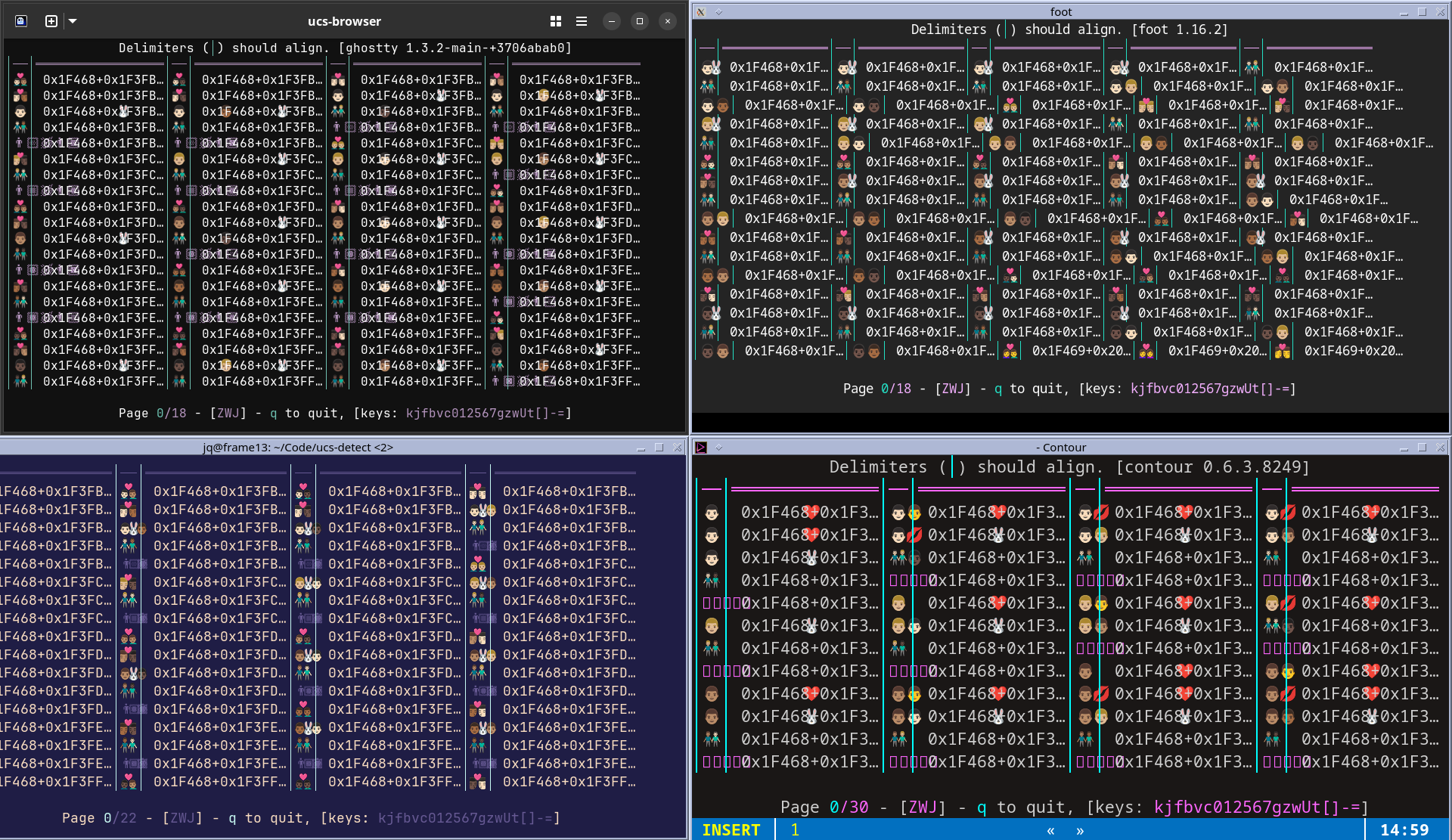
Linux screenshots of Mode 2027-enabled Ghostty, foot, WezTerm, and Contour
Varying feature and version support levels of Unicode are likely to expand and diversify over time. The results of ucs-detect show that any specialized "with or without" grapheme width function is not reasonable. My answer is wcstwidth(), which corrects width measurements for the terminal in use.
Correction Tables
My most important work this year is the new wcstwidth() function, a variant of the Python wcwidth library wcswidth() function that provides corrected width measurements by the terminal software used to call it.
This is made possible by ucs-detect, which across approximately 35 terminals reports every measurement that deviates from wcwidth's specification; wcstwidth() makes use of this data in the form of "correction tables" to return a "corrected" measurement:
>>> import wcwidth >>> wcwidth.wcwidth('🧟♂') 2 >>> wcwidth.wcstwidth('🧟♂', term_program='VTE') 8
This work is needed at least until the Kitty Text Sizing Protocol is supported by a majority of terminals, or until the Unicode Terminal WG begins to publish standards that are then also adopted by a majority of terminals.
In movwin: My (unpublished) TUI framework movq wrote
movwin must know how many cells in the terminal a Unicode sequence will (probably) occupy. The big problem here is that this depends on the terminal, so it can't ever be perfect.
Challenge accepted: I propose that it can be perfect!
Kitty Text Sizing Protocol
A complementary general-purpose solution to the sizing problem is the Kitty Text Sizing Protocol (KTSP). By surrounding the text with a KTSP sequence, reliable width presentation of graphemes beyond 2 cells is possible:
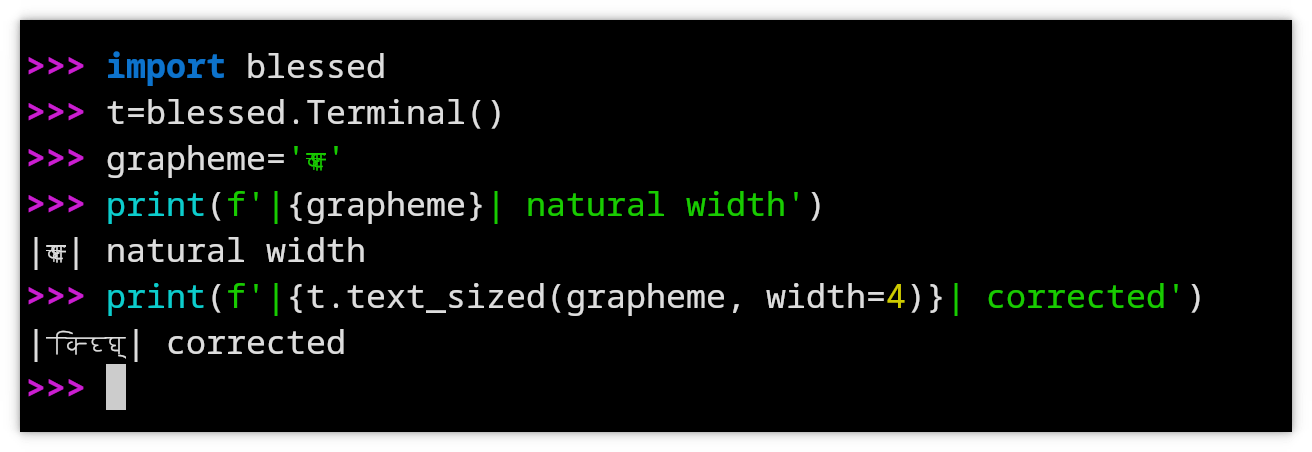
Screenshot of the Python blessed library method text_sized() to correct a width of 4 for a very wide Virama using the Kitty Text Sizing Protocol.
This technique of correcting for complex scripts using KTSP is written about in more detail in Rendering complex scripts in terminal and OSC 66 (Thottingal, 2026).
This is a very good solution for general text sizing issues in terminals; I hope to see it integrated into more TUI applications as a solution to the general problem of emoji/grapheme width in more REPLs, text editors, and terminals.
I've integrated it into my own public projects, adding does_text_sizing() and text_sized() to the blessed library to detect and construct KTSP sequences, updating the wcwidth library's width() function to measure width of text containing KTSP sequences, so that it may be aligned with any of the center(), ljust(), rjust() and high-level functions wrap() and clip().
I have also changed ucs-detect to report scores as '100' (perfect) for Unicode categories when KTSP is supported.
blessed demonstration script, scroller.py showing a classic demoscene scroller effect using the text sizing protocol
Identification
There is one drawback: we can only provide corrections for terminals that can be identified.
For terminals with a unique TERM environment value, alacritty, contour, foot, rio, rxvt, screen, st, tmux, ghostty, and kitty, this is fairly reliable, as TERM is forwarded over almost all protocols (SSH, Telnet, even rlogin), though some connections such as serial do not forward TERM.
The TERM_PROGRAM environment variable uniquely identifies Apple Terminal, Hyper, iTerm.app, mintty, Tabby, terminology, vscode (xterm.js), WarpTerminal, and WezTerm. However, TERM_PROGRAM is not forwarded over SSH without ssh_config(5) SendEnv and sshd_config(5) AcceptEnv configuration, so it is not reliable for remote connections.
The most reliable method of identifying a terminal over any protocol is by querying XTVERSION ('\x1b[>q'), supported by 21 terminals. PuTTY, Extraterm, and rxvt still respond to the older ENQ ('\05') with an automatic "answerback" response. The ENQ sequence is responsible for the confusing insert of a PuTTYPuTTYPuTTYPuTTY into your shell prompt after accidentally displaying binary data.
It is also possible to rapidly identify a terminal by querying the terminal with the Cursor Position Report sequence while using a binary-search of known Unicode measurement quirks.
Terminal Multiplexers
Terminal multiplexers are excluded from offering correction tables for the same reason I exclude them from my personal workflow: their results are inconsistent depending on the host terminal and often confuse their cursor position.
ucs-detect tests these multiplexers using ghostty as a "host terminal", but their displayed width and cursor location will vary depending on the host terminal, and automatic replies of the cursor position report can become mismatched to their actual position. This problem compounds in the complexity of its corruption and cursor placement.

Alignment issues compound with terminal multiplexers. Zellij's model of cursor position reports a width 1, while ghostty correctly displays a width of 2. Note the corruption of zellij's window border of the same line.
API improvements
The Python wcswidth() function strays from POSIX wcswidth(3) definition:
This implementation differs from Markus Kuhn's original POSIX C implementation, in that this wcswidth() processes grapheme strings returned by iter_graphemes() defined by Unicode Standard Annex #29. POSIX wcswidth(3) is not grapheme-aware and does not measure many kinds of emoji or complex scripts correctly.
The existing wcswidth() interface is a natural fit to measure a series of codepoints by their grapheme boundaries. The context of surrounding codepoints is required to accurately measure them, and the grapheme boundary is a standards-defined break.
POSIX wcwidth(3) and wcswidth(3) return -1 for C0 and C1 control codes like TAB or sequences beginning with ESC. This signals the caller to manage these "terminal functions" itself. In practice, many TUI applications just sum the results, discarding -1 values.
After auditing all downstream uses of wcswidth() regarding graphemes and the handling the possible -1 return values, I wrote, "about every downstream library has some issue with the POSIX wcwidth and wcswidth functions."
I made several new releases to address common needs:
- An easy-to-use width() function as a wrapper around wcswidth() capable of measuring most terminal control codes and sequences, like colors, bold, tabstops, and horizontal cursor movement.
- Text-justification functions ljust(), rjust(), center(), and the grapheme-aware function wrap(), serving as drop-in replacements for Python standard functions.
- strip_sequences() removes terminal escape sequences from text altogether.
- clip() for substrings by displayed column positions.
- iter_graphemes() and iter_sequences() for careful navigation of graphemes and terminal sequences as required by editors or REPLs with cursor control, and its complementary iter_graphemes_reverse() and grapheme_boundary_before() functions for backward cursor control.
I then suggested and contributed improvements to many downstream dependencies: asciimatics#396, prettytable#440, prettytable#452, Pylsy#42, pyte#206, pytermgui#166, python-ftfy#227, python-prompt-toolkit#2045, rich#3956, table2ascii#137, and urwid#1100,
Before and after screenshots of rich#3956.
Setting limits on Grapheme widths
Prior to wcwidth 0.8.0, a single grapheme could measure as wide as 3, 4, or even 5 cells. This was driven by a complex Virama conjunct algorithm for Brahmic scripts such as Javanese, where a sequence of consonant, virama, consonant, and combining mark (Mc) could accumulate width. The algorithm roughly matched web browser width of Virama.
ucs-detect testing of approximately 35 terminals revealed a clear pattern: most grapheme-aware terminals supporting Mode 2027 rarely advance a single grapheme beyond 2 cells. And so the specification and implementation of wcwidth 0.8.0 have been updated with the rule, "Any grapheme cluster width is limited to 2 cells since 0.8.0" to match majority support.
Crushing long Virama chains into two cells is often illegible. It is, nevertheless, a fair compromise for the typewriter and teletype cellular grid constraints of a terminal design.
Continuing On
These correction tables have been years in the making. I hope they serve you well. If you'd like to browse unicode and the correction tables yourself, try ucs-browser and use 't' hotkey to toggle correction tables:
uvx --from ucs-detect ucs-browser
If you found this work useful, please consider sponsering me on GitHub.