This is a follow-up to my previous article, Terminal Emulators Battle Royale – Unicode Edition! from 2023, in which I documented Unicode support across terminal emulators. Since then, the ucs-detect tool and its supporting blessed library have been extended to automatically detect support of DEC Private Modes, sixel graphics, pixel size, and software version.
The ucs-detect program tests terminal cursor positioning by sending visible text followed by control sequences that request the cursor position. The terminal responds by writing the cursor location as simulated keyboard input. The ucs-detect program reads and compares these values against the Python wcwidth library result, logging any discrepancies.
The Width Problem
Terminal emulators face a fundamental challenge: mapping the vast breadth of Unicode scripts into a fixed-width grid while maintaining legibility. A terminal must predict whether each character occupies one cell or two, whether combining marks overlay previous characters, and how emoji sequences collapse into single glyphs.
These predictions fail routinely. Zero-width joiners, variation selectors, and grapheme clustering compound in complexity. When terminals and CLI applications guess wrong, text becomes unreadable - cursors misalign and corrupt output and so then also corrupt the location of our input.
Our results share which terminals have the best "Unicode support" -- the least likely to exhibit these kinds of problems.
The Gentleman Errant
Before presenting the latest results, Ghostty warrants particular attention, not only because it scored the highest among all terminals tested, but that it was publicly released only this year by Mitchell Hashimoto. It is a significant advancement. Developed from scratch in zig, the Unicode support implementation is thoroughly correct.
In 2023, Mitchell published Grapheme Clusters and Terminal Emulators, demonstrating a commitment to understanding and implementing the fundamentals. His recent announcement of libghostty provides a welcome alternative to libvte, potentially enabling a new generation of terminals on a foundation of strong Unicode support.
The Errant Champion
Kovid Goyal's Kitty scored just as well, only outranked by the arbitrary weights that are not necessarily fair. More important than scoring is Kovid's publication of a text-splitting algorithm description that closely matches the Python wcwidth specification. This is unsurprising since both are derived from careful interpretation of Unicode.org standards and that it scores so highly in our test.
Kitty and Ghostty are the only terminals that correctly support Variation Selector 15, I have not written much about it because it is not likely to see any practical use, but, it will be added to a future release of Python wcwidth now that there are multiple standards and reference implementations in agreement.
Testing Results
The first table, General Tabulated Summary describes unicode features of each terminal, then, a brief summary of DEC Private Modes, sixel support, and testing time.
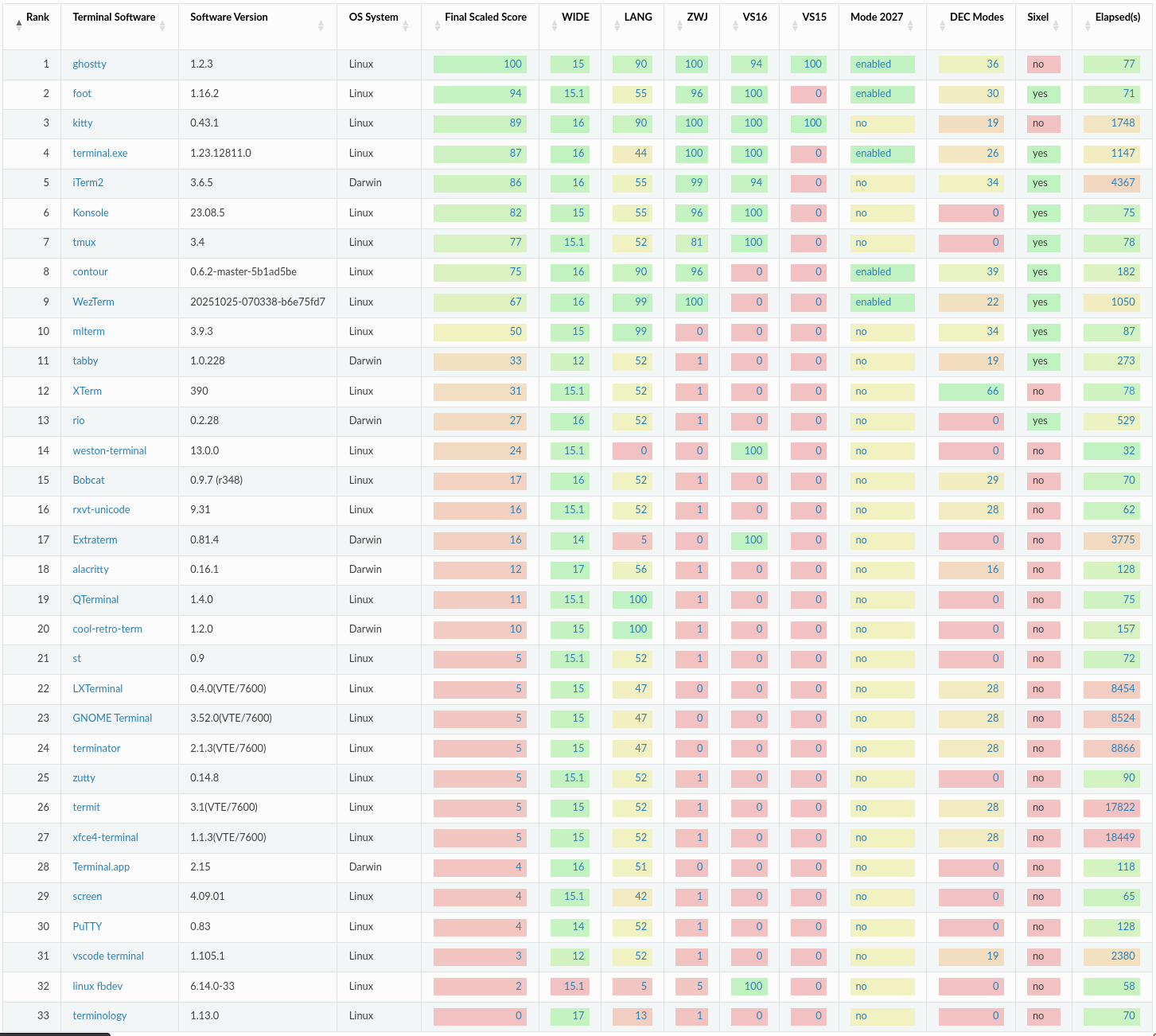
Screenshot of results published at https://ucs-detect.readthedocs.io/results.html
The second table, DEC Private Modes Support (not pictured), contains the first feature capability matrix of DEC Private Modes for Terminals of any length. I hope this is useful most especially to developers of CLI libraries and applications.
The Long Road
The most notable finding relates to performance. That many terminals perform so slowly was surprising, so I have included the elapsed time in the results.
iTerm2 and Extraterm consume a majority of the CPU and perform so slowly that the test parameters were reduced to finish within the hour what many other terminals manage in a few minutes.
GNOME Terminal and its VTE-based derivatives also perform too slowly for a full test, taking over 5 hours while consuming very little CPU. Many terminals exhibit stalls or inefficiencies in their event loops that result in slow automatic responses, but we should be forgiving; nobody really considered the need to handle hundreds of automatic sequence replies per second!
I expected Python wcwidth to consume the most CPU resources during testing, as it is frequently called and always the "highest-level" language in the mix, but it keeps up pretty well for most terminals.
Earlier this year, I dedicated effort to optimizing the Python wcwidth implementation using techniques including bit vectors, bloom filters, and varying sizes of LRU caches. The results confirmed that the existing implementation performed best: a binary search with a functools.lru_cache decorator.
The LRU cache is effective because human languages typically use a small, repetitive subset of Unicode. The ucs-detect tool tests hundreds of languages from the UDHR dataset, excluding only those without any interesting zero or wide characters. This dataset provides an extreme but practical demonstration of LRU cache benefits when processing Unicode.
I previously considered distributing a C module with Python wcwidth for greater performance, but the existing Python implementation keeps up well enough with the fastest terminals. When fully exhausted the text scroll speed is fast enough to produce screen tearing artifacts.
Tilting at Edges
Terminology produces inconsistent results between executions. Our tests are designed to be deterministic, so these kinds of results suggest possible state corruption. Despite this issue, Terminology offers interesting visual effects that would be a welcome feature in other terminals.
iTerm2 reports "supported, but disabled, and cannot be changed" status for all DEC Private Modes queried, including fictional modes like 9876543. For this reason, the summary of DEC Private Modes shows only those modes that are changeable.
Konsole does not reply to queries about DEC Private modes, but does support several modes when they are enabled. For this reason, ucs-detect cannot automatically infer which DEC Modes Konsole supports.
Similarly, ucs-detect reports "No DEC Private Mode Support" for Contour. I investigated this discrepancy because Contour's author also authored a Mode 2027 specification dependent on this functionality. The issue was that Contour responded with a different mode number than the one queried. While developing a fix, Contour's latest release from December 2024 presented an additional complication: a bad escape key configuration. Each instance of being stuck in vi required typing CTRL + [ as a workaround!
Terminals based on libvte with software version label VTE/7600 continue to show identical performance with low scores in our tests, unchanged from 2023.
My attempt to discuss improving Unicode support in libvte received substantial criticism. However, recent libvte project issue Support Emoji Sequences is a positive indicator for improved language and Emoji support in 2026.
On Mode 2027
I included DEC Private Mode 2027 in the results to accompany Mitchell's table from his article, Grapheme Clusters and Terminal Emulators, and to verify for myself that it has limited utility.
In theory, a CLI program can query this mode to classify a terminal as "reasonably supporting" unicode, but not which specific features or version level. Since other terminals with similar capabilities do not respond to Mode 2027 queries, this binary indicator has limited utility.
The only practical approach to determining Unicode support of a terminal is to interactively test for specific features, codepoints, and at the Unicode version levels of interest, as ucs-detect does.
Beyond Fixed Widths
Terminals cannot reproduce many of the world's languages legibly when constrained to monospace cells. The measurements dictated by rapidly expanding Unicode standards and varying implementation levels create inherent tension.
The text sizing protocol published early this year represents a significant development. Kovid Goyal describes the motivation in a recent interview:
And then my next windmill that I'm looking at is variable-sized text in the terminal. So when I'm catting a markdown file, I want to see the headings big.
While this feature may enable more advanced typesetting-like capabilities in terminal apps, it also promises to increase accessibility. Allowing text to escape monospace constraints enables legible support of the diverse set of the world's languages.
For example, using Contour with ucs-detect --stop-at-error=lang, stopping to take a look at a result of the language Khün:
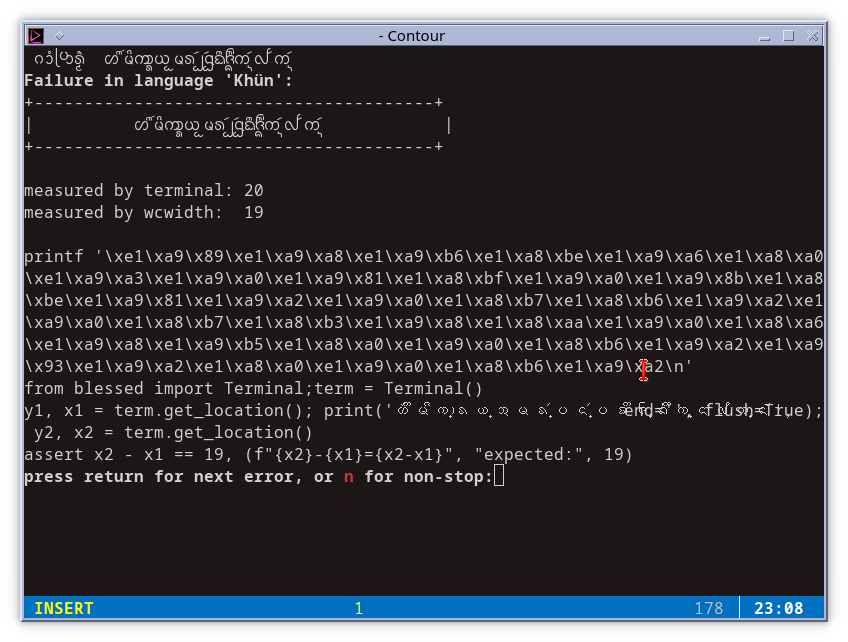
In this case Contour and Python wcwidth disagree on measurement, but more important is the legibility. We can compare this given Khün text to the Kate editor:
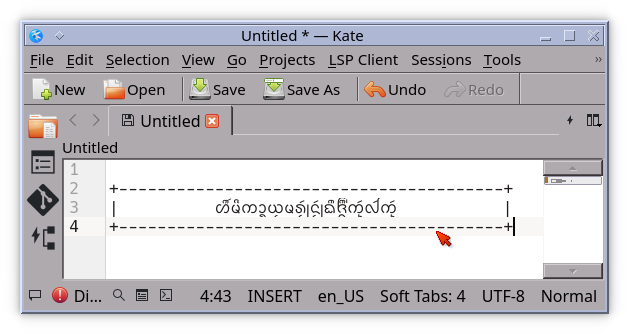
They are clearly different. I regret I cannot study it more carefully, but I suggest that terminals could more easily display complex scripts by switching to a variable size text mode, allowing the font engine to drive the text without careful processing of cell and cursor movement.
Although I have yet to experiment with it, I am encouraged to see some resolution to this problem by the progressive changes suggested by the text sizing protocol.