It turns out that Unicode support in Terminals is a lot more difficult than it first appears. A quick overview of special support for Unicode characters in Terminals:
- "Wide" or "Fullwidth" characters, particularly for East Asian languages and emojis, are codepoints that occupy two cells in a terminal instead of one.
- "Zero" width combining characters used in languages such as Arabic, Hebrew, or Hindi do not occupy any cells themselves; instead, they modify the previous character.
- "Zero Width Joiner" (ZWJ U+200D) reduces and combines many codepoints into a single emoji. This is similar to combining, but encoded in a completely different way.
- "Variation Selector-16" (VS-16 U+FE0F) is a special character that, for specific "Narrow" emojis consuming one cell, causes them to become "Wide", consuming two cells.
I share maintenance of the python wcwidth library, which is responsible for determining the printable width of a string when displayed to a terminal. I worked hard to close all open issues, adding support for VS-16, ZWJ, and several bug fixes to the Zero-Width table definitions.
Additionally, I authored a Specification of how the Python wcwidth library measures characters. Then, I updated the python ucs-detect tool to systematically asses terminal emulators for their compliance with the specification.
Finally, I have published results for the most popular terminal emulators on Linux, macOS, and Windows. This article is a summary of my findings.
Wide Character support
Across all unicode capabilities tested, Wide character support is best. This is likely attributed to the widespread adoption of emojis, which are treated as wide characters, generating interest across developers and users of all languages.
While all tested terminals demonstrate support for wide characters, there are variations in the Unicode versions they support. Notably, Konsole, iTerm2, and Kovid Goyal's kitty support wide characters up to Unicode release version 15.0.0 (2022). In contrast, Hyper and Visual Studio Code, both built on xterm.js, provide support only up to Unicode release 12.1.0 (2019).
This means that these wide characters take up 1 cell instead of 2, often occluded by the next character.
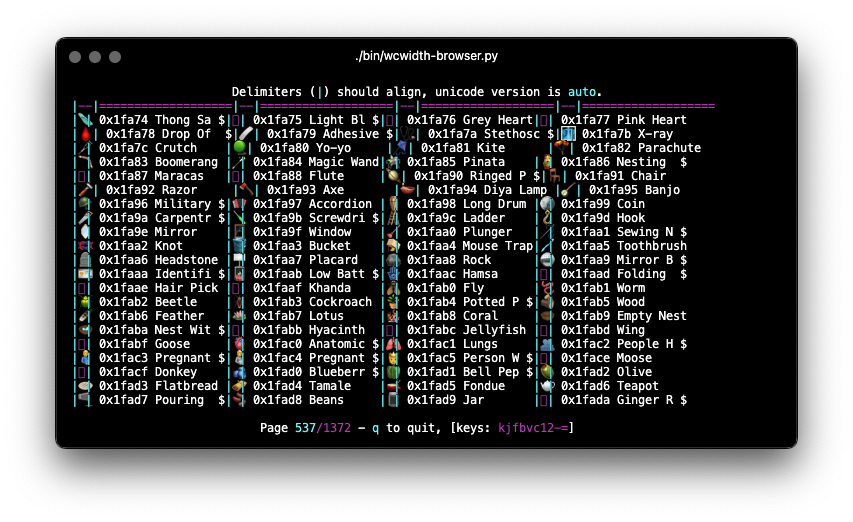
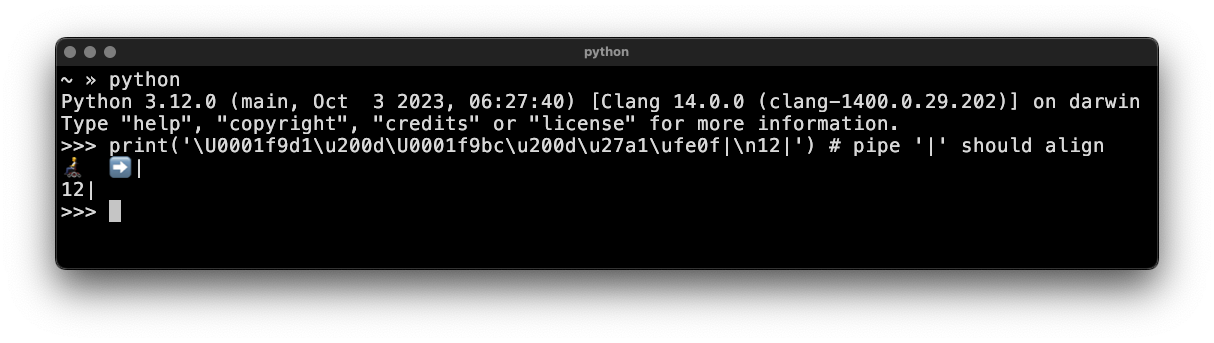
Pictured here in Hyper terminal, the Python wcwidth developer tool wcwidth-browser.py shows several Wide Emoji mistakenly displayed as Narrow instead of Wide, due to out-of-date code tables in xterm.js, causing some to be partially occluded by the Pipe character (|).
The Python wcwidth project Specification describes Wide characters as:
> Any character defined by East Asian Fullwidth (F) > or Wide (W) properties in EastAsianWidth txt > files, except those that are defined by the > Category codes of Nonspacing Mark (Mn) and > Spacing Mark (Mc).
The "except" clarification is needed, as there are several characters officially categorized as Wide or Fullwidth, but contradictory definitions of Zero by other data files!
The definition continues:
> Any characters of Modifier Symbol category, > 'Sk' where 'FULLWIDTH' is present in comment > of unicode data file, aprox. 3 characters.
The definition is further expanded to include any characters falling within the Modifier Symbol 'Sk' category, specifically those with 'FULLWIDTH' mentioned in the comment field of the Unicode data file—approximately three characters in total.
This clause is crucial for a small set of characters from the modifier symbol category that, while not officially designated as Fullwidth or Wide, indeed exhibit these properties. Detecting these characters necessitates parsing the comment field of the data files.
The "Modifier Symbol" category is a strange category. It is a set of combining characters that do not act as combining characters, they are for lone display, except for the Emoji Modifier Fitzpatrick codepoints, which modify the skin tone of the preceding Emoji in sequence, making it a kind of combining character unlike all other characters of this category.
How difficult! The Unicode.org data files present contradictory categorizations. It's no wonder that developers, even those that strive for full compliance, can still encounter difficulty in accurately categorizing a small percentage of characters.
Zero Width
Testing support for Zero Width characters poses a particular challenge. While it may be possible to combine some combining characters with any other Unicode characters, like U+0309 "Combining Hook Above" with box drawing character U+2532:
> ┲̉
Hoever, this is not the case for most combining characters, which can only combine with specific characters. For instance, U+094D "Devanagari Sign Virama" successfully combines with an appropriate Devanagari letter, like U+0915 "Devanagari Letter Ka":
> क्
However, it fails to combine for non-Devanagari letters, such as U+0061 "Latin Small Letter A":
> a्
The "dotted donut" depicted after "Latin Small Letter A" is used as a placeholder for these illegal combinations.
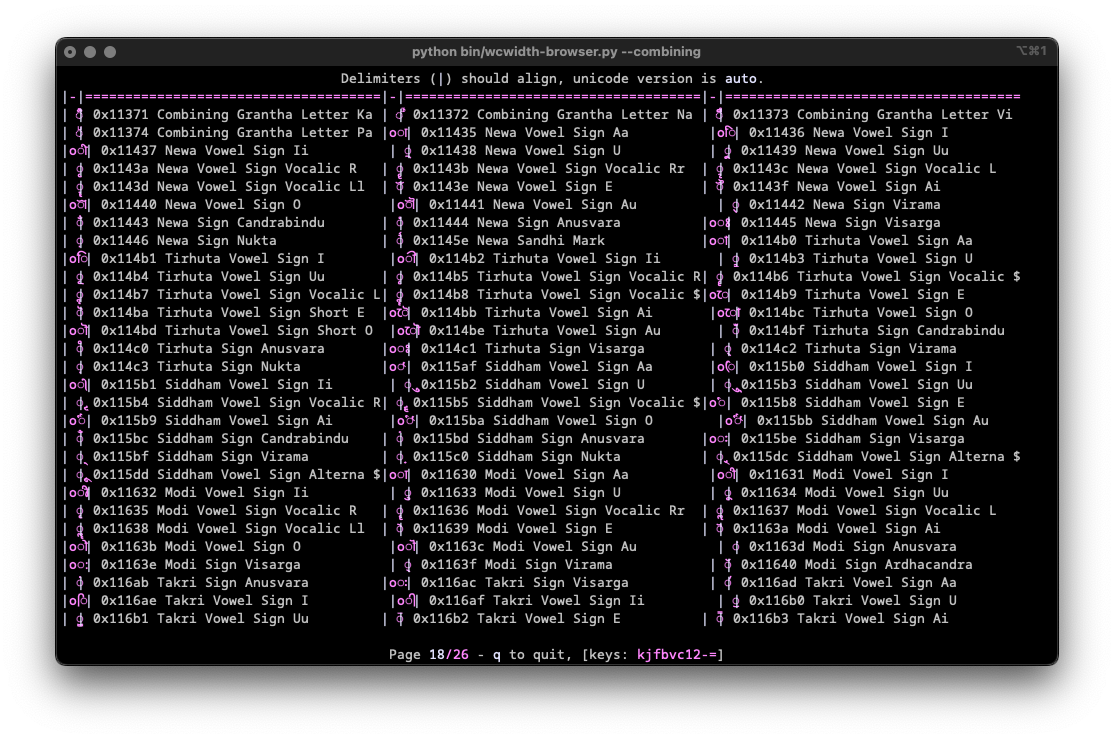
Depicted here in iTerm2 are several combining characters after U+0007 "Latin Small Letter O", where many fail to combine, resulting in the display of a "dotted donut".
To explore and visualize combining characters in a naive manner, you can use the developer tool wcwidth-browser.py from the Python wcwidth repository. Press 'c' after launch or use the CLI argument --combining. However, this tool serves primarily to demonstrate that naive combining is not feasible for a vast number of characters.
A Rosetta Stone?
The Universal Declaration of Human Rights (UDHR) is a remarkable document translated to over 500 languages. The UDHR Unicode project curates a collection of these translations, offering a valuable resource for testing support of Zero-Width characters.
Outside of Emoji, we really only care about whether any particular language is supported, and for many languages, Zero-Width characters are necessary to properly write them.
Using the ucs-detect tool to display phrases from UDHR in each language and measuring the displayed width, we can conduct a comprehensive test for Zero-Width character support of each Terminal by Language.
Zero Width Results
The Windows-only terminals, Terminal.exe, cmd.exe, and ConsoleZ, as well as the cross-platform ExtraTermQt and for-pay commercial zoc terminal all fail to correctly display many Zero-Width characters, failing for approximately 100 of the world's languages.
The common error of these terminals is that they account category codes Nonspacing Mark (Mn) and Spacing Mark (Mc) as Narrow instead of Zero width.
One example of the Hindi language from ConsoleZ where the U+093e of 'Mc' category is incorrectly measured as Narrow:
| Codepoint | Python | Category | wcwidth | Name |
|---|---|---|---|---|
| U+092E | '\u092e' | Lo | 1 | DEVANAGARI LETTER MA |
| U+093e | '\u093e' | Mc | 0 | DEVANAGARI VOWEL SIGN AA |
| U+0928 | '\u0928' | Lo | 1 | DEVANAGARI LETTER NA |
| U+0935 | '\u0935' | Lo | 1 | DEVANAGARI LETTER VA |
- python wcwidth.wcswidth() measures width 3, while ConsoleZ measures width 4.
And another, of the Vietnamese language, from Microsoft's Terminal.exe, where U+0300 "Combining Grave Accent" of the 'Mn' Category is incorrectly measured as Narrow:
| Codepoint | Python | Category | wcwidth | Name |
|---|---|---|---|---|
| U+0074 | 't' | Ll | 1 | LATIN SMALL LETTER T |
| U+006F | 'o' | Ll | 1 | LATIN SMALL LETTER O |
| U+0061 | 'a' | Ll | 1 | LATIN SMALL LETTER A |
| U+0300 | '\u0300' | Mn | 0 | COMBINING GRAVE ACCENT |
| U+006E | 'n' | Ll | 1 | LATIN SMALL LETTER N |
- python wcwidth.wcswidth() measures width 4, while Microsoft's Terminal.exe measures width 5.
It is understandable that these category codes are not considered for Zero-Width support by so many other wcwidth and terminal developers. Unicode.org documents make only general statements about the purpose of these categories and they do not make any direct statements about Terminal Emulators. Developers must then seek for answers among thousands of pages of documents that can be cryptic and verbose. Without a search engine and a "hunch", it would be very difficult to discover naturally!
From Standard Annex #24 Unicode Script Property:
> Implementations that determine the boundaries > between characters of given scripts should never > break between a combining mark (a character with > General_Category value of Mc, Mn or Me)
And, from Unicode Standard Annex #14 Unicode Line Breaking Algorithm:
> The CM line break class includes all combining > characters with General_Category Mc, Me, and Mn, > unless listed explicitly elsewhere. This includes > viramas that don’t have line break class VI or VF.
Variation Selector-16
U+FE0F "Variation Selector-16" is peculiar.
I suspect it is some kind of "fixup" or compatibility sequence for the earliest emojis. These emojis may be displayed in either "text" or "emoji" style, and default to "text" style. In "text" style, emojis should appear without color in a single cell (Narrow), while in "emoji" style, they should display in color and occupy two cells (Wide).
Despite this distinction, very few fonts effectively differentiate between the two styles, often rendering both types in color. When not in sequence with U+FE0F "Variation Selector-16", they are occluded by any next character.
For example, U+23F1 "Stopwatch":
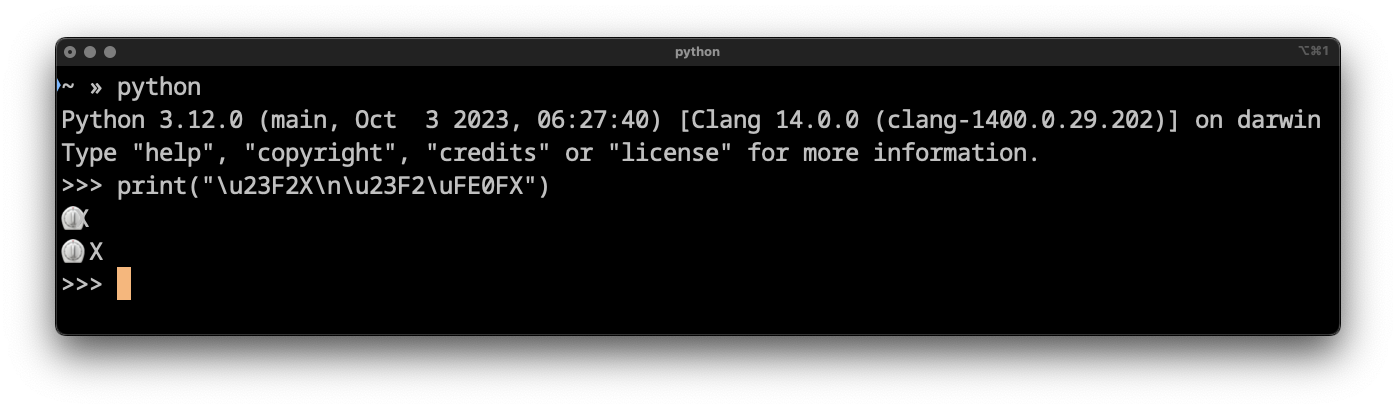
Depicted here in iTerm2 is a single U+23F1 "Stopwatch" character partially occluded by any next character. Surprisingly, this is the correct behavior of a terminal when U+FE0F "Variation Selector-16" is not in sequence.
From Python wcwidth Specification on Wide characters:
> Any character in sequence with `U+FE0F`_ > (Variation Selector 16) defined by Emoji > Variation Sequences txt as ``emoji style``.
A list of such characters is found in emoji-variation-sequence.txt.
VS-16 Results
Out of the 23 terminals subjected to testing, only 7 demonstrated correct behavior by displaying these emojis as "Wide" characters when combined with VS-16 in sequence.
Remarkably, I found scarce documentation, if any, about VS-16 and its effects in terminals. The absence of documentation on this matter was the primary motivation for writing this article.
Wezterm, for example, excels in complying with all other Unicode specifications outlined in this article and tested by ucs-detect. However, like 16 other terminals tested, it falls short in supporting VS-16. These emojis are consistently occluded by the next character, even when in sequence with VS-16.
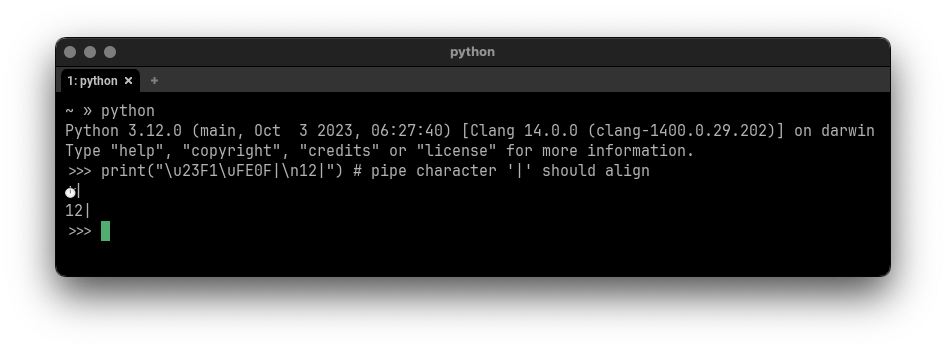
Depicted here in Wezterm is U+23F1 "Stopwatch" followed in sequence by U+FE0F "Variation Selector-16". However, the stopwatch is displayed as Narrow. Wezterm does however do a good job of scaling the font to fit within a single cell, while most other terminals cause it to be partially occluded by any next character.
Emoji ZWJ
U+200D "Zero Width Joiner" is a special character facilitating the reduction of multiple emojis into a single representation that embodies their combination. This feature resembles a special case of combining, but it is encoded in a completely different manner.
The Python wcwidth Specification on "Width of 0" reads:
> Any character following a ZWJ (U+200D) when > in sequence by function wcwidth.wcswidth().
An instance of a terminal lacking ZWJ support is Kovid Goyal’s kitty. It's important to note that this terminal should not be confused with KiTTY, another terminal emulator sharing a similar name but predating it by 14 years. Mr. Goyal expresses particular hostility about this naming conflict.
| Codepoint | Python | Category | wcwidth | Name |
|---|---|---|---|---|
| U+0001F9D1 | '\U0001f9d1' | So | 2 | ADULT |
| U+200D | '\u200d' | Cf | 0 | ZERO WIDTH JOINER |
| U+0001F9BC | '\U0001f9bc' | So | 2 | MOTORIZED WHEELCHAIR |
| U+200D | '\u200d' | Cf | 0 | ZERO WIDTH JOINER |
| U+27A1 | '\u27a1' | So | 1 | BLACK RIGHTWARDS ARROW |
| U+FE0F | '\ufe0f' | Mn | 0 | VARIATION SELECTOR-16 |
- python wcwidth.wcswidth() measures width 2, while Kovid Goyal's kitty measures width 6.
In this kitty example, the depicted sequence is expected to measure a width of 2. However, kitty measures it as 6 because it does not interpret the Zero Width Joiner character to reduce the three wide characters into one.
Concluding remarks
I intend to use this article as a reference when filing bug reports in open source projects. I hope you appreciate the effort invested in writing a clear Specification within the python wcwidth library and the ucs-detect tool, systematically testing terminals for compliance with the specification.
Additionally, it is worth nothing that the python wcwidth project systematically generates code lookup tables for Wide, Zero-Width, and VS-16 sequences. These tables are created using update-tables.py, which fetches the latest data from unicode.org. The project utilizes jinja2 templates to transform that data into Python code.
This can be easily extended for languages like C/C++, Rust, Ruby, Go, or any other. Feel free to contribute new code templates to Python wcwidth project for seamless integration with your preferred language.
Finally, I strongly advocate for Python to internally implement some version of Python wcwidth. Functions like str.ljust(), textwrap.wrap(), or format strings such as f'{my_string:<{width}}' should inherently account for the width of non-ascii characters when formatting strings. Presently, these functions rely solely on the count of characters without understanding their printed width. I believe this adversely affects many developers who discover 'the hard way' that an external library is necessary. Given that Python wcwidth is downloaded over 50 million times per month, incorporating this functionality into Python should be a sound and economically sensible decision.
I've discovered a Draft standard for C++, P1868R0 that proposes adding this support, and I wholeheartedly endorse this direction. While I'm unsure of its acceptance, I'm inclined to submit a similar proposal for the Python language (Issue #94). Equipped with a concise Specification, I encourage fellow developers to embark on similar initiatives for all modern programming languages.